混沌工程
[TOC]
混沌工程
By:weimenghua
Date:2022.11.20
Description:混沌工程
参考资料
awesome-chaos-engineering
awesome-chaosblade
ChaosBlade 官网
ChaosBlade 文档
ChaosBlade 源码
1. 混沌工程
参考资料
混沌工程介绍与实践
1.1 定义
混沌工程不是无目的地随机注入故障而是通过精心计划的实验在受控环境中注入故障,以建立对应用程序和工具的信心,以承受动荡的条件。
1.2 目的
混沌工程的目的是给复杂的分布式系统引入扰动,并观察系统行为,借此发现系统弱点。
混沌工程进行的是探索系统复杂性的开放实验,目的是改善原有的系统架构和运维模式,加强业务服务的健壮性。
1.3 过程
1、通过创建破坏性事件(例如服务器中断或 API 限制)来对测试或生产环境中的应用程序施加压力
2、观察系统如何响应
3、实施改进
1.4 意义
让我们对未知做好了准备: 1、提高了系统弹性 2、暴露监控、可观察性和警报盲点 3、提高恢复时间和操作技能
1.5 模型
混沌工程实验模型
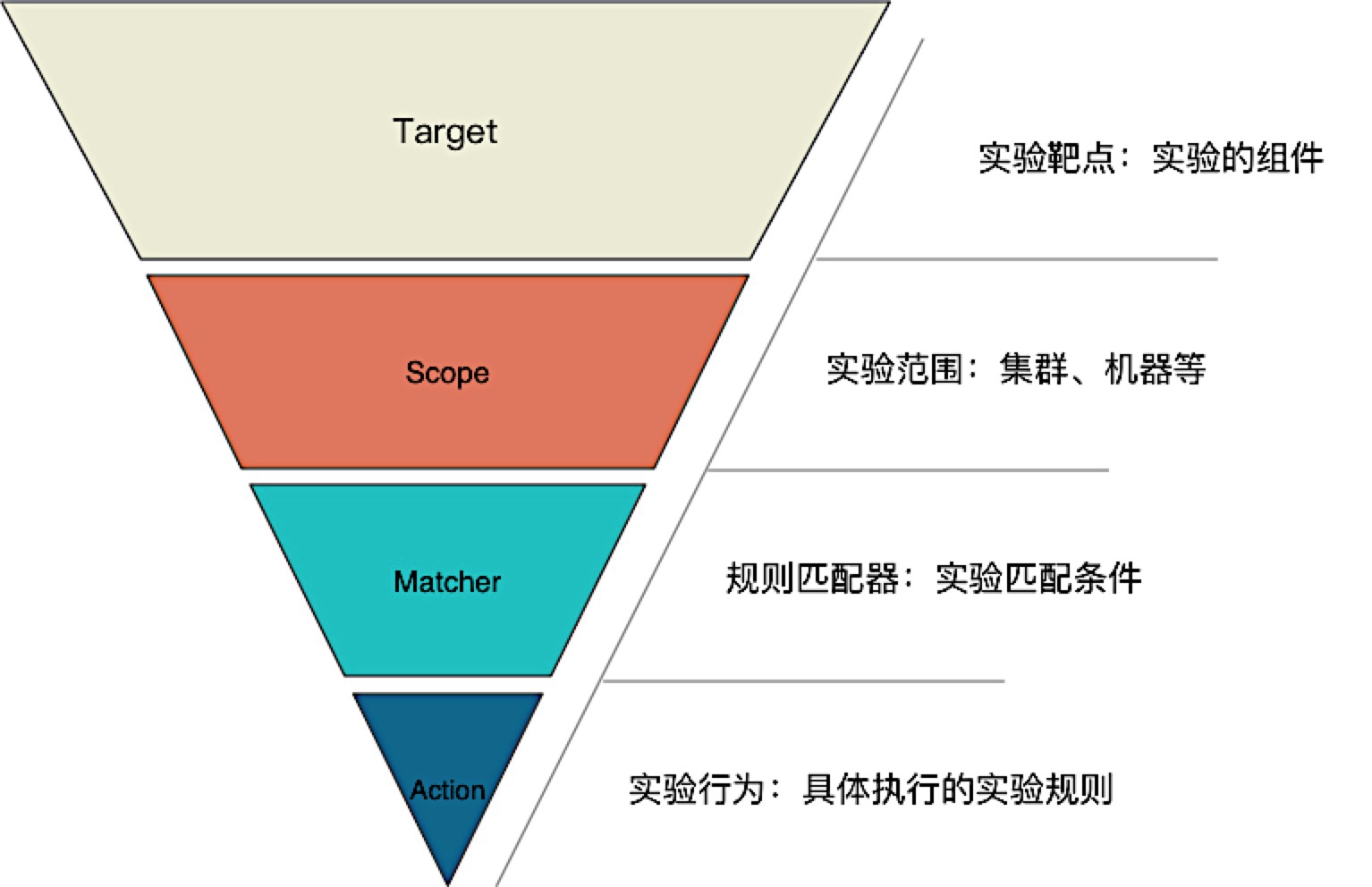
混沌工程实验:一个持续性迭代的闭环体系
架构抵御故障的能力:通过对实验对象的架构高可用性的分析和评估,找出潜在的系统单点风险,确定合理的实验范围。
实验指标设计:评估目前实验对象判定业务正常运行所需的业务指标、应用健康状况指标和其他系统指标。
实验环境选择:选择实验对象可以应用的实验环境:开发、测试、预生产、生产。
实验工具使用:评估目前实验对象对实验工具的熟悉程度。
故障注入场景及爆炸半径:讨论和选择可行的故障注入场景,并评估每个场景的爆炸半径。
实验自动化能力:衡量目前实验对象的平台自动化实施能力。
环境恢复能力:根据选定的故障注入场景,评估实验对象对环境的清理和恢复能力。
实验结果整理:根据实验需求,讨论确定实验结果和解读分析报告的内容项。
故障注入测试:故障注入测试是从系统的故障状态开始,测试系统在发生故障后的运行规律。
2. 故障类型
2.1 系统故障
- cpu 负载高
- 内存负载高
- 磁盘负载高
- 集群重启
2.2 中间件故障
- 主备切换
- 数据库-连接数满
2.3 应用故障
- 服务重启
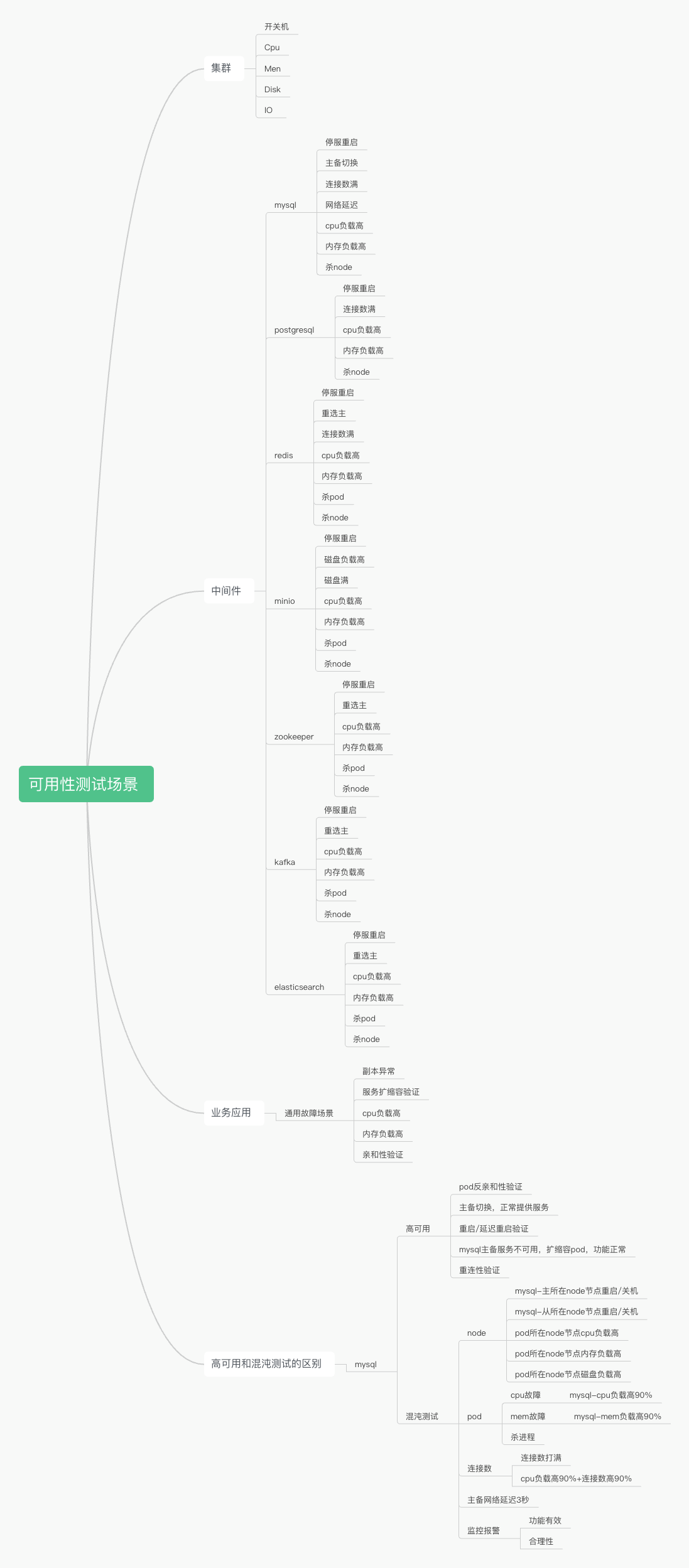
3. 可用性测试场景
4. 高可用测试
4.1 高可用简介
高可用定义 高可用(High availability,即 HA)的主要目的是为了保障「业务的连续性」,即在用户眼里,业务永远是正常(或者说基本正常)对外提供服务的。
高可用标准 衡量可靠性的标准——X个9,这个X是代表数字3~5。X个9表示在软件系统1年时间的使用过程中,系统可以正常使用时间与总时间(1年)之比。
- 1个9:(1-90%)*365=36.5天,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是36.5天
- 2个9:(1-99%)*365=3.65天 , 表示该软件系统在连续运行1年时间里最多可能的业务中断时间是3.65天
- 3个9:(1-99.9%)36524=8.76小时,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是8.76小时
- 4个9:(1-99.99%)36524=0.876小时=52.6分钟,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟
- 5个9:(1-99.999%)36524*60=5.26分钟,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟
- 6个9:(1-99.9999%)365246060=31秒, 示该软件系统在连续运行1年时间里最多可能的业务中断时间是31秒
4.2 相关概念
- 亲和性 亲和性调度是指通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活
亲和性(Affinity)主要分为三类:
- 节点亲和性(nodeAffinity):以node为目标,解决pod可以调度到哪些node的问题。
- pod亲和性(podAffinity):以pod为目标,解决pod可以和哪些已经存在pod部署到同一个拓扑域中的问题。
- pod反亲和性(podAntiAffinity):以pod为目标,解决pod不能和哪些已存在的pod部署在统一个拓扑域中的问题。 亲和性和反亲和性说明
- 亲和性:如果两个应用频繁交互,那就有必要利用亲和性让两个应用尽可能靠近,这样可以减少因网络通信而带来的性能损耗。
- 反亲和性:当应用采用多副本部署时,有必要采用反亲和性让各个应用实例分布在各个node节点上,这样可以提高服务的高可用性。
- 有状态/无状态
有状态服务 无状态控制器:ReplicaSet、ReplicationController、Deployment。
- 无状态服务内的多个Pod创建的顺序是没有顺序的。创建的pod序号都是随机值。并且在缩容的时候并不会明确缩容某一个pod,而是随机的,因为所有实例得到的返回值都是一样,所以缩容任何一个pod都可以。
- 无状态服务内的多个Pod的名称是随机的,pod被重新启动调度后,它的名称与IP都会发生变化。
- 无状态服务内的多个Pod背后是共享存储的,该服务运行的实例不会在本地存储需要持久化的数据。(有冲突?)
- 多个实例对于同一个请求响应的结果是完全一致的。
- 无状态服务 有状态服务的工作负载: StatefulSet。 有状态服务可以说是需要数据存储功能的服务、或者指多线程类型的服务,队列等。(mysql数据库、kafka、zookeeper等)每个实例都需要有自己独立的持久化存储,并且在k8s中是通过申明模板来进行定义。持久卷申明模板在创建pod之前创建,绑定到pod中,模板可以定义多个。 唯一性: 每个Pod会被分配一个唯一序号。 顺序性: Pod启动,更新,销毁是按顺序进行。 稳定的网络标识: Pod主机名,DNS地址不会随着Pod被重新调度而发生变化。 稳定的持久化存储: Pod被重新调度后,仍然能挂载原有的PV,从而保证了数据的完整性和一致性。
总结:Stateful有状态服务,每个Pod有独立的PVC/PV存储组件。
强依赖/弱依赖
熔断/降级/限流 熔断器模式(Circuit Breaker Pattern),是一个现代软件开发的设计模式。用以侦测错误,并避免不断地触发相同的错误(如维护时服务不可用、暂时性的系统问题或是未知的系统错误)。 假设有个应用程序每秒会与数据库沟通数百次,此时数据库突然发生了错误,程序员并不会希望在错误时还不断地访问数据库。因此会想办法直接处理这个错误,并进入正常的结束程序。
重启策略 在k8s集群中有如下三种重启策略:
- Always:当容器终止退出后,总是重启容器,默认策略。
- OnFailure:当容器异常退出(退出状态码非0)时,重启容器。
- Never:当容器终止退出,从不重启容器。 重启策略适用于pod对象中的所有容器,首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长为10s,20s,40s,80s,160s,300s,300s是最大延迟时长。 重启策略设置建议: 因为重启策略默认的是Always,这也是合理的,因此在一般情况下,重启策略不需要设置,这里仅仅是作为知识点拿出来展示一下,在实际使用中,在大多数情况下都不需要进行重启策略配置。
- 故障类型
- k8s之连接异常(集群故障)
- k8s之通信异常(网络故障)
- k8s之内部异常(节点异常)
- k8s之应用故障(应用异常)